আগে আমরা প্রজেক্ট বানিয়েছিলাম এবার মডেল বানিয়ে বাকি কাজগুলো করবো
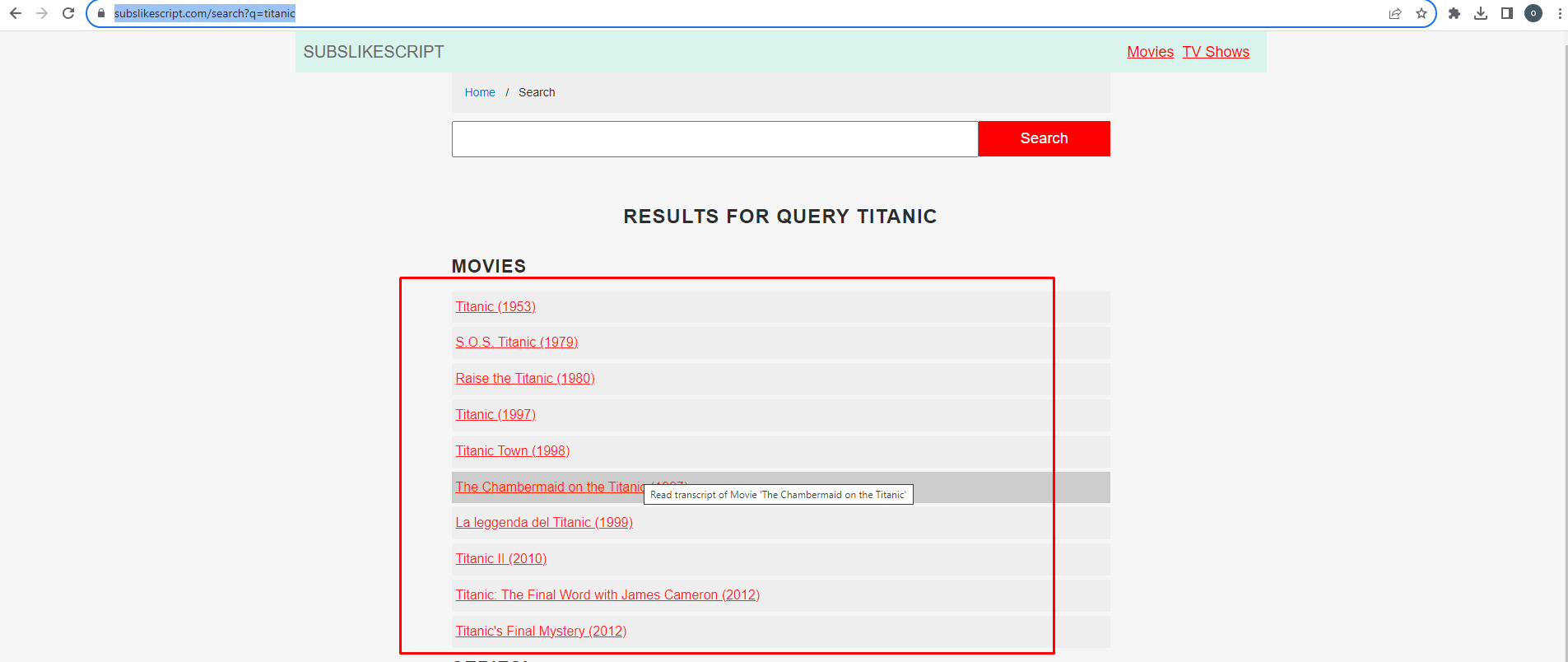
এই টিউটোরিয়ালে আমরা এই ওয়েবসাইটের https://subslikescript.com/ যেকোনো পেজ (সিঙ্গেল পেজ না ) এর প্রথম পেজ থেকে লিংক ও টাইটেল স্ক্রাপ করে csv ফাইল আকারে ডাউনলোড করতে পারবো। এজন্য আমাদের pandas ইন্স্টল্ করতে হবে।
pip install pandasmyapp/models.py
from django.db import models
class ScrapedData(models.Model):
title = models.CharField(max_length=255,default="")
description = models.TextField(default="")
def __str__(self):
return self.titleMigrate Database
python manage.py makemigrations
python manage.py migrateforms.py
# myapp/forms.py
from django import forms
class ScrapeForm(forms.Form):
url = forms.CharField(max_length=100, widget=forms.TextInput(attrs={'placeholder': 'Enter URL'}))
myapp/views.py
from django.shortcuts import render
from django.http import HttpResponse
from .forms import ScrapeForm
from .models import ScrapedData
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Create your views here.
def scrape_and_save(request):
if request.method == 'POST':
form = ScrapeForm(request.POST)
if form.is_valid():
url = form.cleaned_data['url']
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
# Extract data from the soup and save to the database
movie_list = soup.find('ul', class_='scripts-list')
root = 'https://subslikescript.com'
link = movie_list.find_all('a', href=True)
data = []
for links in link:
title = links.text.strip()
url = f'{root}{links["href"]}'
data.append({'Title': title, 'URL': url})
# Convert data to DataFrame
df = pd.DataFrame(data)
# Convert DataFrame to CSV
csv_data = df.to_csv(index=False)
# Set up HTTP response
response = HttpResponse(csv_data, content_type='text/csv')
response['Content-Disposition'] = 'attachment; filename="scraped_data.csv"'
return response
else:
form = ScrapeForm()
return render(request, 'search.html', {'form': form})
templates/search.html
<!-- myapp/templates/scrape.html -->
<form method="post" >
{% csrf_token %}
{{ form.as_p }}
<button type="submit">Scrape and Save</button>
</form>
urls.py
from django.urls import path
from .views import scrape_and_save
urlpatterns = [
path('scrape/', scrape_and_save, name='scrape_and_save'),
]